
Computer-Science-A-level-Ocr
-
3-3-networks8 主题
-
3-2-databases7 主题
-
3-1-compression-encryption-and-hashing4 主题
-
2-5-object-oriented-languages7 主题
-
2-4-types-of-programming-language4 主题
-
2-3-software-development5 主题
-
2-2-applications-generation6 主题
-
2-1-systems-software8 主题
-
1-3-input-output-and-storage2 主题
-
1-2-types-of-processor3 主题
-
1-1-structure-and-function-of-the-processor1 主题
-
structuring-your-responses3 主题
-
the-exam-papers2 主题
-
8-2-algorithms-for-the-main-data-structures4 主题
-
8-1-algorithms10 主题
-
7-2-computational-methods11 主题
-
7-1-programming-techniques14 主题
-
capturing-selecting-managing-and-exchanging-data
-
entity-relationship-diagrams
-
data-normalisation
-
relational-databases
-
hashing
-
symmetric-vs-asymmetric-encryption
-
run-length-encoding-and-dictionary-coding
-
lossy-and-lossless-compression
-
polymorphism-oop
-
encapsulation-oop
-
inheritance-oop
-
attributes-oop
-
methods-oop
-
objects-oop
-
capturing-selecting-managing-and-exchanging-data
-
6-5-thinking-concurrently2 主题
-
6-4-thinking-logically2 主题
-
6-3-thinking-procedurally3 主题
-
6-2-thinking-ahead1 主题
-
6-1-thinking-abstractly3 主题
-
5-2-moral-and-ethical-issues9 主题
-
5-1-computing-related-legislation4 主题
-
4-3-boolean-algebra5 主题
-
4-2-data-structures10 主题
-
4-1-data-types9 主题
-
3-4-web-technologies16 主题
-
environmental-effects
-
automated-decision-making
-
computers-in-the-workforce
-
layout-colour-paradigms-and-character-sets
-
piracy-and-offensive-communications
-
analysing-personal-information
-
monitoring-behaviour
-
censorship-and-the-internet
-
artificial-intelligence
-
the-regulation-of-investigatory-powers-act-2000
-
the-copyright-design-and-patents-act-1988
-
the-computer-misuse-act-1990
-
the-data-protection-act-1998
-
adder-circuits
-
flip-flop-circuits
-
simplifying-boolean-algebra
-
environmental-effects
hashing
Hashing
What is hashing?
-
In A Level Computer Science, hashing is a method to convert any data into a fixed-size string of characters
-
This fixed-size output is often called a digest

-
Same input will always produce the same hash, providing consistency
-
Even a minor change in input produces a radically different hash, giving it sensitivity to data changes
|
Input Text |
Hashing Algorithm |
Truncated Hash Digest |
|---|---|---|
|
“hello123” |
SHA-256 |
|
|
“hello124” |
SHA-256 |
|
|
“applepie” |
SHA-256 |
|
|
“bpplepie” |
SHA-256 |
|
|
“password1” |
SHA-256 |
|
|
“password2” |
SHA-256 |
|
Some common hashing algorithms are:
-
MD5 (Message Digest 5)
-
Widely used but considered weak due to vulnerabilities to collision attacks
-
-
SHA-1 (Secure Hash Algorithm 1)
-
Previously used in SSL certificates and software repositories, now considered weak due to vulnerabilities
-
-
SHA-256 (Part of the SHA-2 family)
-
Commonly used in cryptographic applications and data integrity checks. Considered secure for most practical purposes
-
-
SHA-3
-
The most recent member of the Secure Hash Algorithm family, designed to provide higher levels of security
-
Comparison of encryption and hashing
Hashing and encryption both turn readable data into an unreadable format, but the two technologies have different purposes.
|
|
Encryption |
Hashing |
|---|---|---|
|
Purpose |
Securing data for transmission or storage; reversible |
Data verification, quick data retrieval, irreversible |
|
Reversibility |
Can be decrypted to the original data |
It cannot be reversed to the original data |
|
Keys |
Uses keys for encryption and decryption |
No keys involved |
|
Processing Speed |
Generally slower for strong encryption methods |
Generally faster |
|
Use Cases |
Secure communications, file storage |
Password storage, data integrity checks |
|
Algorithm Types |
Symmetric, Asymmetric |
MD5, SHA-1, SHA-256, etc. |
|
Security |
Varies; potentially strong but dependent on key management |
One-way function makes it secure but susceptible to collisions |
|
Data Length |
Output length varies; could be same or longer than input |
Fixed length output |
|
Change in Output |
Small change in input results in significantly different output |
Small change in input results in significantly different output |
|
Typical Operations |
Encrypt, Decrypt |
Hash, Verify |
Hashing for password storage
-
Hashing is commonly used for storing passwords
-
When the user first signs up, the password they provide is hashed
-
The hashed password is stored in the database, rather than as plaintext
-
When users try to log in, they enter their username and password
-
The system hashes the password entered by the user during the login attempt
-
The hashed password is compared against the stored hash in the database
-
If the hashes match, the user is authenticated and granted access
-
If they don’t match, access is denied
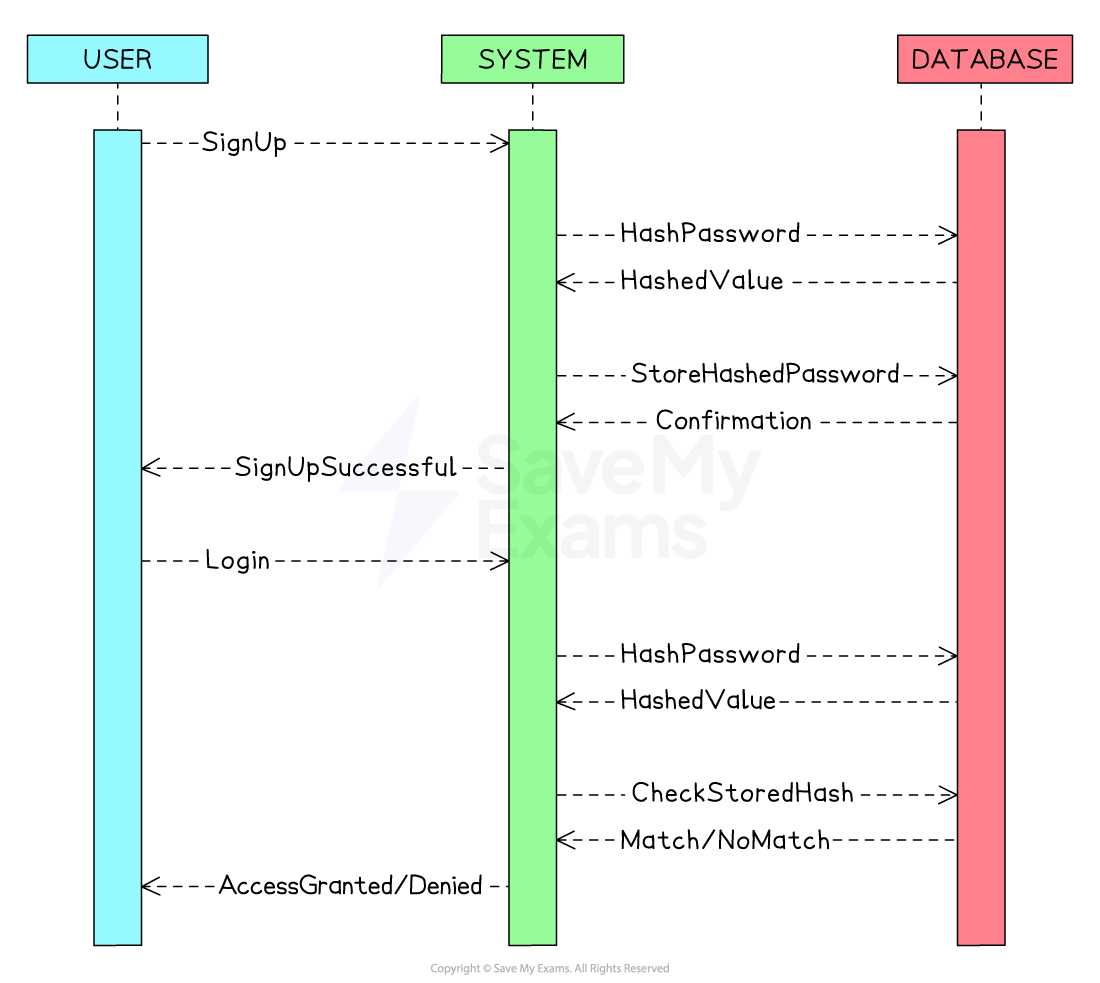
-
Hashing passwords adds an extra layer of security
-
Even if the database is compromised, the attacker can’t use the hashed passwords directly
-
In case of a data breach, not storing passwords in plaintext minimises the risk and potential legal repercussions
-
Users’ raw passwords are not exposed, reducing the impact of a data breach
-
Since the hash function always produces the same output for the same input, verifying a user’s password is quick
Why is hashing an efficient method for data retrieval?
Database lookup
-
A good hash function uniformly distributes keys across the hash table, allowing for a more balanced and efficient data retrieval
-
In the example below, the hashed Users table for a website is shown
-
The hashed table has no order
-
New users are randomly inserted into the hash table, which leads to a uniform distribution
-
If the website application needs to fetch the user’s data from the table, it is computationally more efficient to query using the hash digest value than any other attribute
-
This is because hash digests have a fixed length, making it easier for the computer to compare hash digests rather than variable-length strings like email addresses
-
|
Hash Table Index |
|
|
|
|
|
|---|---|---|---|---|---|
|
Hash Digest |
|
|
|
|
|
|
Email Address |
|
|
|
|
|
|
Sign-Up Date |
|
|
|
|
|
-
The hash digest serves as a summarised representation of the data (email address in the above example)
Data integrity
-
Another benefit of hashing data is being able to verify its integrity
-
When data is being transferred over a network, it is susceptible to loss of packets or malicious interference, so if two hashes are compared and are identical, it allows a system to verify the integrity of data
-
This is because the same data hashed by the same hashing function will produce the same digest
-
Comparing two fixed-size hashes is computationally less intensive than string comparison
Worked Example
A developer is designing a network security system. She is developing a component that logs websites users can access. This software records the websites’ URLs and details about the allowed users and their access times.
For each website, the following details are captured:
-
Required user rank (A-D)
-
If it’s accessible 24/7 (true) or only during breaks and outside office hours (false)
For instance, a website that can be accessed by users of rank B and higher throughout the day would have the data [B, true] associated with it.
A site that ranks C and above users but only outside office hours would be recorded as [C, false].
Identify an appropriate data structure to keep the details of a single website.
[1]
Answer:
Answer that gets full marks:
Hash table or tuple.
Worked Example
Every website’s URL, along with its corresponding data, is saved in a hash map.
The hash function of this map processes the website’s URL (serving as the key). The hashing procedure is as follows:
-
Remove characters up to and inclusive of the first dot.
-
Eliminate characters from and after the next dot present.
-
Convert the remaining string to uppercase.
-
Sum up the ASCII values of the characters.
Given the ASCII values for the letters:
Responses